In a previous blog post, we showed how “bringing the code to the data” can highly improve computation performance through the active storage (also known as computational storage) concept. In our journey in investigating how to best make computation and storage ecosystems interact, in this blog post we analyze a somehow opposite approach of “bringing the data close to the code“. What the two approaches have in common is the possibility to exploit data locality moving away in both cases from the complete disaggregation of computation and storage.
The approach in focus for this blog post, is at the basis of the Alluxio project, which in short is a memory speed distributed storage system. Alluxio enables data analytics workloads to access various storage systems and accelerate data-intensive applications. It manages data in-memory and optionally on secondary storage tiers, such as cheaper SSDs and HDDs, for additional capacity. It achieves high read and write throughput unifying data access to multiple underlying storage systems reducing data duplication among computation workloads. Alluxio lies between computation frameworks or jobs, such as Apache Spark, Apache MapReduce, or Apache Flink, and various kinds of storage systems, such as Amazon S3, OpenStack Swift, GlusterFS, HDFS or Ceph. Data is available locally for repeated accesses to all users of the compute cluster regardless of the compute engine used avoiding redundant copies of data to be present in memory and driving down capacity requirements and thereby costs.
For more details on the components, the architecture and other features please visit the Alluxio homepage. In the rest of the blog post we will present our experience in integrating Alluxio on our Ceph cluster and use a Spark application to demonstrate the obtained performance improvement (the reference analysis and testing we aimed to reproduce can be found here).
The framework used for testing
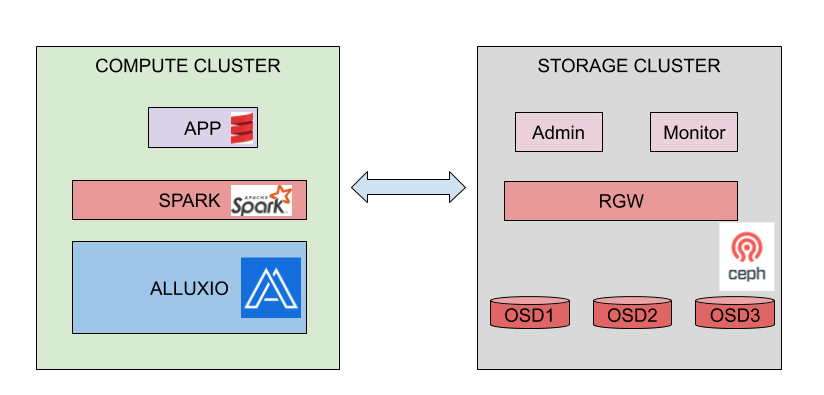
Our framework set-up used for testing is drafted in Fig. 1. The underlying storage we used is Ceph (version mimic) and its object storage. The Ceph cluster we used for testing purposes has been deployed over 6 OpenStack VMs, hosting respectively one Ceph monitor, three storage devices running Object Storage Devices (OSDs), one Ceph RADOS Gateway (RGW) node and one administration node. The total storage size of 420GiB was spread over 7 OSD volumes attached to the three OSD nodes. More details about the Ceph cluster deployment can be found in our previous blog post.
For the computation side, Alluxio (v2.3) has been installed on a separate VM where also Spark (v3.0.0) services are running. Two different settings have been tested. The first set-up we have the simple case with one single VM (16vCPUs) dedicated to Alluxio and Spark master and worker nodes (with 40GB of memory for the worker node). In the second set-up, a cluster mode has been tested where two additional Spark and Alluxio worker nodes are configured (with 16vCPUs and 40GB of memory).
An application has been written in Scala to be run over Spark. The simple code performed access to a text file and count operation over the lines in the file. A comparison in terms of execution time was in focus when the file is either accessed directly through the Ceph RGW on the underlying storage system or through Alluxio. In the latter case, the first time the file has been accessed, Alluxio will upload the file from the underlying Ceph storage into the memory. The subsequent file access will then hit the in-memory copy stored in Alluxio. As we will see, this introduces important performance improvements.
Some preliminary results
We considered three different file sizes, i.e., 1GB, 5GB and 10GB. In each test we stored the time to access the file the first and the second time (averaged over 10 runs). The same application is then launched again a second time to measure again the same file access times. The aim of this is to show how the in-memory Alluxio caching introduces benefits also for further applications accessing the same data.
As it can be noticed from the results plotted in Fig. 2 and Fig. 3, besides the first time when Alluxio is accessing the file and storing it in memory before performing the text line count, very large performance improvements are obtained in comparison to direct Ceph access in all cases. The best performance improvements are observed the second time the file is accessed. For the single node analysis presented in Fig. 2, the second time the file is accessed directly on Ceph the measured time is 75 times higher for the 1GB file, 111 and 107 times higher for the 5GB and 10GB file respectively compared to the access over Alluxio. For the cluster mode setup, the overall execution time is much lower in all cases, and the second time the file is accessed directly on Ceph the measured time is 35 times higher for the 1GB file, 57 and 65 times higher for the 5GB and 10GB file respectively compared to the access over Alluxio.
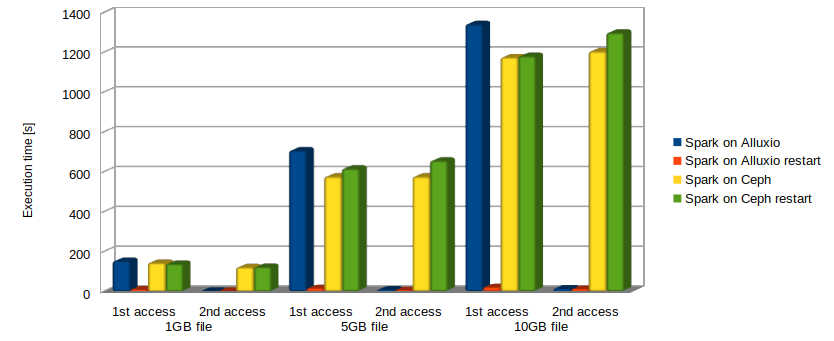
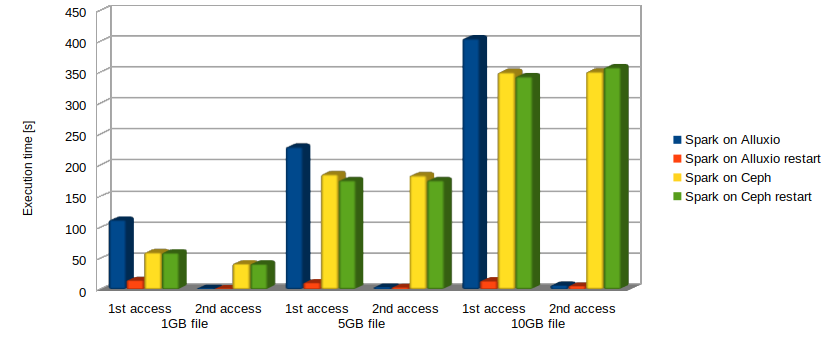
The obtained results confirm our expectation that disaggregation of computation and storage is probably not always the best approach to follow. In our vision, a smart combination of bringing data to the code and code to the data approaches is the way to go for optimizing performance. Clearly, this depends on the scenarios and the use cases with several policies that could be put in place to best tune the behaviour/performance.
The Scala code snippets
The Scala code to be run in Spark is reported below in case the same tests should be reproduced. The specific case is here configured to access a 10GB file Ceph directly through the RGW.
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import java.io.File
import java.io.PrintWriter
object test extends App
{
val testcase="10gb-file"
val writer = new PrintWriter(new File("Log_"+testcase+"_Ceph_2nd"))
val conf = new SparkConf().setAppName("test").setMaster("spark://10.20.0.120:7077")
val sc = new SparkContext(conf)
var totaltime : Long=0
var firsttime :Long=0
var totalsecondtimes :Long=0
var avgsecondtimes :Long=0
var newtime : Long=0
for( i<- 0 to 10)
{
val file = sc.textFile("s3a://my-new-bucket/" + testcase )
if (i == 0)
{
val start=System.nanoTime()
file.count()
val end = System.nanoTime()
firsttime = (end-start)/1000000
totaltime = totaltime+firsttime
writer.write("Current " + firsttime.toString() + "ms Avg_2nd 0ms" + " Total " + totaltime.toString() + "ms\n")
}
else
{
val start=System.nanoTime()
file.count()
val end = System.nanoTime()
totalsecondtimes = totalsecondtimes+(end-start)/1000000
avgsecondtimes = totalsecondtimes/(i)
totaltime = totaltime+(end-start)/1000000
writer.write("Current " + ((end-start)/1000000).toString() + "ms Avg_2nd " + avgsecondtimes.toString() + "ms Total " + totaltime.toString() + "ms\n")
}
}
writer.close()
}When accessing the file through Alluxio, the code has a minor difference in configuration. Moreover, since the file is explicitly stored in Alluxio memory the first time it is accessed, some additional code lines are needed.
...
for( i<- 0 to 10)
{
val file2 = sc.textFile("alluxio://alluxio:19998/" + testcase + "_cached")
if (i == 0)
{
val file = sc.textFile("alluxio://alluxio:19998/"+ testcase)
val start=System.nanoTime()
file.saveAsTextFile("alluxio://alluxio:19998/" + testcase +"_cached")
file2.count()
val end = System.nanoTime()
firsttime = (end-start)/1000000
totaltime = totaltime+ firsttime
writer.write("Current " + firsttime.toString() + "ms Avg_2nd 0ms" + " Total " + totaltime.toString() + "ms\n")
}....The Scala project is compiled using the sbt tool and the resulting jar is then provided to Spark using spark-submit.
sbt assembly
spark-submit ./target/scala-2.11/test-assembly-1.0.jarSome Spark configuration information
To interface Spark with Ceph the spark-defaults.conf file has to be configured as follows.
spark.driver.extraClassPath /opt/spark/jars/hadoop-aws-3.2.0.jar
spark.executor.extraClassPath /opt/spark/jars/hadoop-aws-3.2.0.jar
spark.driver.extraClassPath /opt/spark/jars/aws-java-sdk-bundle-1.11.375.jar
spark.executor.extraClassPath /opt/spark/jars/aws-java-sdk-bundle-1.11.375.jar
spark.hadoop.fs.s3a.impl org.apache.hadoop.fs.s3a.S3AFileSystem
spark.hadoop.fs.s3a.access.key ########
spark.hadoop.fs.s3a.secret.key ########
spark.hadoop.fs.s3a.connection.ssl.enabled false
spark.hadoop.fs.s3a.signing-algorithm S3SignerType
spark.hadoop.fs.s3a.path.style.access true
spark.hadoop.fs.s3a.endpoint http://10.20.0.156:7480Note that, to interface with Ceph the needed jars had to be downloaded. For our specific Spark with Hadoop installation the with Hadoop 3.2.0 we needed the following jars:
ubuntu@spark:/opt/spark/jars$ sudo wget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aws/3.2.0/hadoop-aws-3.2.0.jar
ubuntu@spark:/opt/spark/jars$ sudo wget https://repo1.maven.org/maven2/com/amazonaws/aws-java-sdk-bundle/1.11.375/aws-java-sdk-bundle-1.11.375.jarTo interface Spark with Alluxio the spark-defaults.conf file had to include the following lines.
spark.driver.extraClassPath /home/ubuntu/alluxio-2.3.0/client/alluxio-2.3.0-client.jar
spark.executor.extraClassPath /home/ubuntu/alluxio-2.3.0/client/alluxio-2.3.0-client.jarOpen issues in testing
Java 8 prerequisite
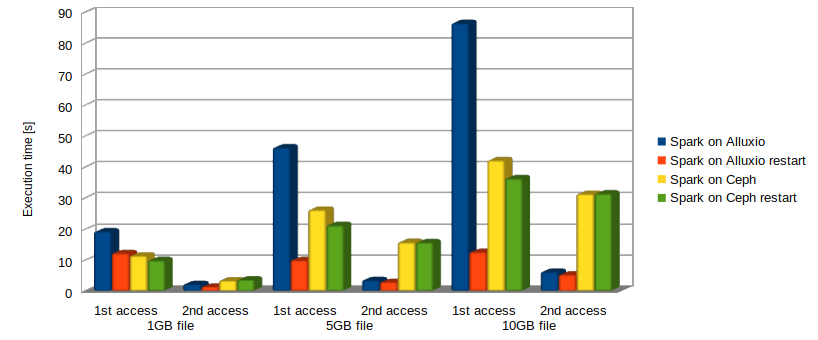
The current stable version of Alluxio (v2.3) has as a prerequisite a version of Java 8 being installed. This means that if the current default Java version, i.e., Java 11 is installed instead, Alluxio will not work. This aspect should be carefully considered when performing the tests presented in this blog. In particular, testing direct Ceph file access with Spark using Java 11 performs much better when compared to using Java 8. Therefore, for a fair comparison of these results always Java 8 should be used also when Alluxio is not used! Work is currently ongoing for Alluxio to use Java 11. In particular, we were able to test v2.4 which is not still released and as expected the total execution time in all cases is largely reduced as we report in Fig. 4. Although the benefits in using Alluxio are a bit downscaled by the general reduced execution time, still a 6 times less execution is obtained for a 10GB file at the second access compared to direct Ceph access.
Default in-memory storage in Alluxio
The first time a file is accessed in Alluxio, this is automatically stored in memory after being this uploaded from the understorage. However, we observed that when accessing this (in-memory) file the second time, a limited performance enhancement is actually observed! We then found out, as reported in the Scala snippet, that when we explicitly use the saveAsTextFile command the first time and then access the new stored file in memory the expected performance improvement is observed. The drawback of this approach is some additional time in saving the file in memory is spent and a redundant copy of the file is stored in memory. We are currently performing further testing to find out whether some parameter or configuration tuning is needed to take advantage directly of the default in-memory caching. Indeed, according to the results we used as a reference for this analysis, Alluxio should provide already a performance increase at the first file access. As we observe from Fig. 2, this is not the case in our analysis due to the additional time needed to execute the saveAsTextFile command.